발제자: 신주희
발제일: 2025년 01월 20일
키워드: [Deep Learning] [Anomaly Detection] [Anomalous Data] [Neural Networks] [Data Mining] [Model Evaluation] [Supervised Learning] [Unsupervised Learning] [Time Series Data] [Anomaly Detection Techniques]
1. Why this paper
- 이상 탐지에 관한 전반적인 지식의 기반을 다지기 위함
- 이상 탐지 문제 복잡성에 따른 미해결 과제 연구
- 한국통신학회 동계 포스터 발표 참고용
2. Abstract
- Anomaly Detection은 수십년 동안 다양한 연구 커뮤니티에서 지속적이고 활발한 연구 분야였으며, 여전히 고급 접근 방식이 필요한 몇 가지 독특한 문제 복잡성과 과제가 남아 있음.
- 최근 몇 년간, 딥러닝을 통한 이상 탐지가 중요하게 다뤄지면서 포괄적인 분류법인 3가지 상위 수준의 범주와 11가지 세분화된 방법의 범주가 떠올랐으며, 이러한 분류법을 사용하여 Deep Anomaly Detection 연구를 수행함.
3. Introduction
- 이상 탐지는 다수의 데이터 인스턴스와 크게 벗어나는 데이터 인스턴스를 탐지하는 과정으로 수십 년간 활발한 연구 분야로 발전해왔음. 이에, 심층 이상 탐지의 중요성이 강조되는데, 고차원/시간적/공간적/그래프 데이터 등 복잡한 데이터의 표현력 있는 특징을 학습하는데 뛰어난 능력이 입증되었음.
- 본 연구의 차별점은 기본 리뷰들은 전통적인 이상 탐지 방법에만 초점이 맞춰져 있고, 응용 사례 중심의 개략적 설명에 그친다는 한계가 있음. 따라서 본 연구에서는 현재 심층 탐지 방법의 공식화를 제시하고, 직관과 내재적 능력에 대한 통찰력을 제공하며, 해결되지 않은 과제들에 대한 분석을 하고자 함.
-
본 논문은 총 5가지를 집중적으로 다룸.
A. Problem nature and challenges : 이상 탐지의 몇 가지 고유한 문제 복잡성과 대부분의 미해결 과제에 대해 논의하고 분석함.
B. Categorization and formulation : 세 가지 원칙적인 프레임워크를 제시함.
- deep learning for generic feature extraction : 일반적인 특징 추출을 위한 딥러닝
- learning representations of normality : 정상성의 표현 학습
-
end-to-end anomaly score learning : 종단간 이상 점수 학습
- 이외에도, 11가지 모델링 관점에 따른 계층적 분류를 제시함.
C. Comprehensive literature review : 여러 관련 커뮤니티의 주요 연구를 검토하여 연구 진행 사황에 대한 포괄적인 문헌 검토를 제시함. 또한, 각 방법론의 기본 가정, 목적 함수, 핵심 직관 설명하여 심층적인 소개를 제공함.
D. Future opportunities : 향후 연구 방향을 논의하고, 관련 과제 해결을 위한 시사점을 제시함.
E. Source codes and datasets : 공개적으로 접근 가능한 소스 코드를 수집하고 실제 이상이 포함된 데이터셋을 제공하며, 실증적 비교 벤치마크를 제공함.
4. Anomaly Detection: Problem Complexities and Challenges
4.1. Major Problem Complexities
- Unknownness : 이상 현상은 예측할 수 없는 행동, 데이터 구조, 분포 등 많은 미지의 요소와 연관됨. 테러 공격, 사기, 네트워크 침입 등은 실제로 발생하기 전까지는 알 수 없음.
- Heterogeneous anomaly classes : 이상 현상은 불규칙적이며, 한 종류의 이상이 다른 종류의 이상과 완전히 다른 특성을 보일 수 있음.
- Rarity and class imbalance : 이상 사례는 전형적으로 희귀한 데이터 인스턴스이므로 정상 인스턴스가 데이터의 압도적 비율을 차지함. 레이블이 있는 비정상 인스턴스를 대량으로 수집하기 어려우며, 이상 인스턴스의 오분류가 정상 인스턴스의 오분류보다 비용이 훨씬 높음.
-
Diverse types of anomaly : 3가지의 완전히 다른 유형의 이상 현상이 조사됨.
A. Point anomalies : 다른 개별 인스턴스들과 비교했을 때 비정상적인 개별 인스턴스
B. Conditional anomalies(Contextual anomalies) : 특정 상황에서 비정상 현상을 보임
C. Group anomalies(Collective anomalies) : 전체적으로 봤을 때 이상으로 간주되는 데이터 인스턴스의 부분집합, 개별 멤버는 정상일 수 있음.
4.2. Main Challenges Tackled by Deep Anomaly Detection
- 아래 문제들은 대부분 해결되지 않음
- CH1: Low anomaly detection recall rate
- 이상이 매우 희귀하고 이질적이어서 모든 이상을 식별하기 어려움
- 많은 정상 인스턴스가 이상으로 잘못 보고되는 반면, 정교한 실제 이상은 놓침
- 현재 최신 기술도 여전히 높은 오탐지율을 보임
- CH2: Anomaly detection in high-dimensional and/or not-independent data
- 저차원 공간에서는 명백한 이상 특성이 고차원에서는 숨겨지고 감지되지 않음
- 복잡한 특성 상호작용과 결합 식별이 중요하나 여전히 주요 과제로 남아있음
- 시간적, 공간적, 그래프 기반 등의 상호의존성을 가진 인스턴스에서의 이상 탐지가 어려움
- CH3: Data-efficient learning of normality/abnormality
- 레이블된 이상 데이터 수집의 어려움으로 정상 및 이상 클래스 모두에 레이블이 지정된 훈련 데이터의 가용성을 가정하기에 비현실적
- 지난 10년간, unsupervised anomaly detection 연구가 집중되었으나, 실제 이상 현상에 대한 사전 지식이 없기에 unsupervised anomaly detection은 이상의 분포에 대한 가정에 크게 의존
- 정상 데이터와 일부 이상 데이터의 레이블을 활용하는 것이 중요
- CH4: Noise-resilient anomaly detection
- 잘못 레이블된 데이터나 레이블되지 않은 이상에 대한 처리 필요함, 이는 실제 레이블이 지정된 데이터를 활용하지 못하는 한계가 있음.
- Noise-resilient model은 정확한 감지를 위해 레이블이 지정되지 않은 데이터(데이터셋마다 노이즈의 양이 크게 다르고 불규칙하게 분포)를 활용할 수 있음.
- CH5: Detection of complex anomalies
- conditional anomaly, group anomaly은 point anomalies과 완전히 다른 동작을 보임.
- 현재는 단일 데이터에서 이상을 감지하는데 중점을 두나, 많은 애플리케이션에서는 다차원 데이터를 활용하므로 multiple heterogeneous data sources에서의 이상 탐지 필요.
- CH6: Anomaly explanation
- 안전이 중요한 도메인에서는 블랙박스 모델 사용의 위험이 존재
- Anomalies로 식별된 이유에 대한 명확한 설명이 필요하며 해석 가능한 이상 탐지 모델 개발이 중요함.
-
Deep Learning Methods vs Traditional Methods in Anomaly Detection

5. Addressing the Challenges with Deep Anomaly Detection
5.1. Preliminaries
- Dataset X
- X는 N개의 데이터 포인트로 이루어져 있음
- 데이터 포인트 Xi는 D차원 벡터
- 표현 공간 Z
- 새로운 저차원 공간인 Z로 Dataset X를 변환하는 것
- 다양한 신경망 구조
- MLP : 완전 연결 레이어로 구성
- CNN : 다양한 합성곱 & 풀링 레이어 그룹이 특징
- RNN : 순환 레이어 기반 (기본 RNN, GRU, LSTM 등)
- 수학적 정의
- Dataset X = {x1,x2,··· ,xN}가 주어졌을 때(xi ∈ RD) A. Z ∈ RK (K ≪ N)를 표현 공간이라 하면, 심층 이상 탐지는 다음 두 가지 함수 중 하나를 학습하는 것을 목표로 함. a1. 특징 표현 매핑 함수 φ(·) : X ↦ Z a2. 이상 점수 학습 함수 τ(·) : X ↦ R
- 딥러닝을 통해 직접 이상 함수를 계산하는 방법을 학습하며, 이상 점수가 클수록 데이터 이상치일 확률이 높으며 이상점수는 신경망이 직접 예측이 가능함.
5.2. Categorization of Deep Anomaly Detection
-
모델링 관점에서 심층 이상 탐지 방법들을 3개의 주요 카테고리와 11개의 세부 카테고리로 분류하는 계층적 분류법을 소개함.
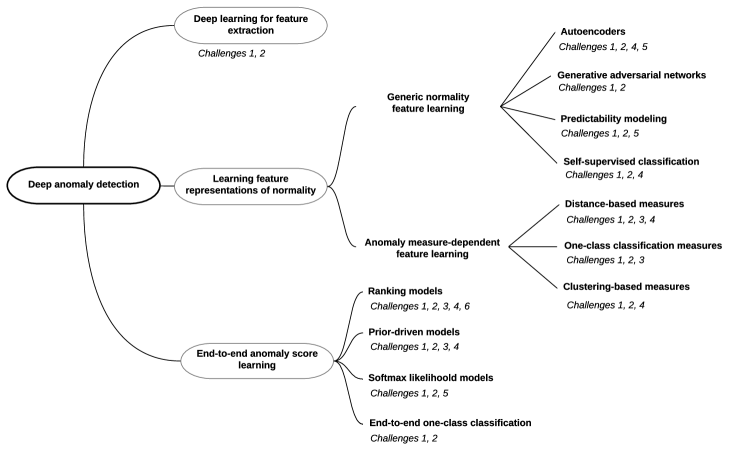
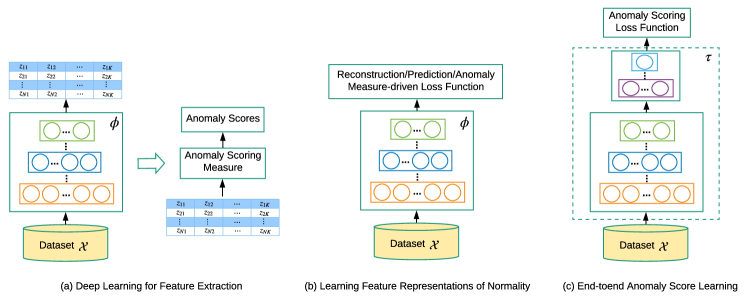
A. Deep learning for feature extraction - 심층 학습과 이상 탐지가 완전히 분리되며 심층 학습은 독립적인 특징 추출기로만 사용됨.
B. Learning feature representations of normality - 심층 학습과 이상 탐지가 어떤 형태로든 상호 의존적이며 정상성의 표현력 있는 특징을 학습하는 것이 목표임.
C. End-to-end anomaly score learning - 심층 학습과 이상 탐지가 완전히 통합됨, 신경망을 통해 이상 점수를 종단간 방식으로 학습되며 이상 점수 학습의 공식화 방식에 따라 4개의 하위 카테고리로 구분됨.
6. Deep Learning for Feature Extraction
- 고차원이나 비선형 분리 가능한 데이터에서 feature representations를 추출하는 것을 목표로 함.
- Feature Extraction과 Feature Extraction이 완전히 분리되어 독립적으로 작동함.
- z = φ(x; Θ)
- X ∈ RD, Z ∈ RK이며 일반적으로 D ≫ K : 특징 매핑 φ와 무관한 이상 점수 계산 방법 f가 새로운 공간에서 이상 점수를 계산하는 데 사용됨.
6.1. 주요 연구 방향
-
사전 학습된 모델 활용
A. AlexNet, VGG, ResNet 등의 사전 학습된 모델을 직접 사용
B. 사례 연구
b1. Unmasking 프레임워크: 연속된 비디오 프레임 간의 구분을 위한 반복적 분류기 학습. b2. VGG 모델을 통한 외관 특징 추출 b3. 전이학습 활용: ILSVRC에서 사전 학습된 모델을 목표 데이터셋에 미세조정 -
명시적 특징 추출 모델 학습
A. 사전 학습된 모델 대신 특징 추출을 위한 심층 모델을 직접 학습
B. 주요 접근법
b1. 다중 autoencoder 네트워크 활용 b2. 합성곱 autoencoder를 통한 특징 추출 후 군집화 b3. 그래프 이상 탐지를 위한 표현 학습 -
이 방법론은 특히 복잡한 고차원 데이터에서 의미 있는 특징을 추출하는데 효과적이나, 특특징 추출과 이상 탐지의 분리로 인한 성능 제한이 주요 한계점으로 지적됨.
7. Learning Feature Representations of Normality
7.1. Generic Normality Feature Learning
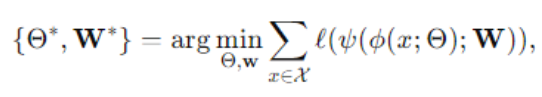
- φ : 원본 데이터를 표현 공간 Z로 매핑
- ψ : 기저 데이터 규칙성 학습을 위한 대리 학습 작업
- ℓ : 손실 함수
-
f : 이상 점수 계산 함수
- 이 계산 과정은 손실 함수 ℓ를 최소화하여 이루어지며, 최적화된 매개변수와 W는 이 과정을 통해 얻어짐을 알 수 있음. 이를 통해 학습된 데이터의 표현이 이상 탐지에 효과적으로 활용됨을 증명함.
(1) Autoencoders
- 목적 : 데이터 인스턴스를 잘 재구성할 수 있는 저차원 특징 표현 공간 학습
- 주요 특징
- 인코딩 네트워크와 디코딩 네트워크로 구성
- 병목 네트워크 구조를 통해 중요 정보만 보존
- 재구성 오차를 이상 점수로 사용
- 주요 변형
- Sparse AE : 은닉층의 활성화 유닛에 희소성 부여
- Denoising AE: 손상된 데이터로부터의 재구성 학습
- Contractive AE : 작은 변화에 강건한 특징 표현 학습
- Variational AE : 잠재 공간에 사전 분포 도입
-
가정 : Normal instance는 compressed space에서 이상치보다 더 재구성이 잘 됨.
- 장점
- 직관적이고 다양한 데이터 유형에 적용 가능
- 다양한 AE 변형 활용 가능
- 단점
- 학습된 특징 표현이 비정규성이나 이상치에 편향될 수 있음
- 목적 함수가 이상 탐지가 아닌 차원 축소에 최적화됨
(2) Generative Adversarial Networks
-
목적 : 정상 데이터의 특성을 잘 포착하는 잠재 특징 공간 학습
- 주요 방법
- AnoGAN: 잠재 공간에서 유사 인스턴스 검색
- EBGAN: 인코더를 추가하여 계산 효율성 개선
- GANomaly: 인코더-디코더-인코더 네트워크로 개선
- 장점
- 현실적인 인스턴스 생성에 뛰어난 능력
- 다양한 GAN 모델과 이론 활용 가능
- 단점
- 학습의 불안정성 (수렴 실패, 모드 붕괴 등)
- 생성기가 정상 인스턴스의 매니폴드를 벗어날 수 있음
- 이상 점수가 데이터 합성에 최적화되어 차선적일 수 있음
7.2. Anomaly Measure-dependent Feature Learning
-
수학적 표현 {Θ, W} = argmin Θ,W Σ(x∈X) ℓ(f(φ(x;Θ);W)) sx = f(φ(x;Θ);W)
- 여기서 f는 표현 공간에서 작동하는 기존의 이상 점수 측정 방식
- 세 가지 주요 측정 방식으로 구분
(1) Distance-based Measure
-
목적 : 특정 거리 기반 이상 측정을 위해 최적화된 특징 표현 학습
- 주요 특징
- 저차원 공간 투영으로 차원의 저주 문제 해결
- 무작위 이웃 거리 기반 이상 측정 활용
- 의사 레이블을 통한 학습 유도
- 장점
- 이론적 근거가 탄탄함
- 고차원 데이터 처리 효과적
- 맞춤형 표현 학습 가능
- 단점
- 계산 비용이 높음
- 거리 기반 측정의 본질적 한계 존재
(2) One-class Classification-based Measure
-
목적 : 단일 클래스 분류를 위한 최적화된 특징 표현 학습
- 주요 방법
- Deep One-class SVM
- Deep SVDD (Support Vector Data Description)
- 장점
- 강력한 이론적 기반
- 통합된 표현 학습과 분류 모델
- 수동 커널 함수 선택 불필요
- 단점
- 복잡한 분포를 가진 데이터셋에서 성능 저하
- 기존 단일 클래스 분류 측정에 의존적
(3) Clustering-based Measure
-
목적 : 새로운 표현 공간에서 이상이 군집과 명확히 구분되도록 학습
- 주요 특징
- 순방향 전달에서 군집화 수행
- 역방향 전달에서 군집 할당을 의사 클래스 레이블로 활용
- GMM 등 다양한 군집화 알고리즘 활용 가능
- 장점
- 다양한 심층 군집화 방법과 이론 활용 가능
- 최적화된 표현 학습으로 이상 탐지 용이
- 단점
- 군집화 결과에 크게 의존
- 훈련 데이터의 이상에 영향 받기 쉬움
- 이러한 접근법들은 공통적으로 다음과 같은 과제들을 해결함
- CH1, CH2, CH3(레이블된 데이터 효율적 활용), CH4(노이즈에 대한 강건성)
8. END-TO-END ANOMALY SCORE LEARNING
-
이전의 이상 측정 의존적 특징 학습과 달리, 이 접근법의 이상 점수 계산은 기존 이상 측정 방식에 의존하지 않고 신경망이 직접 이상 점수를 학습함.
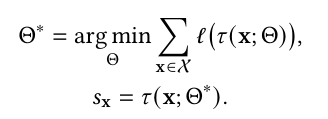
- 주요 특징
- 신경망이 직접 이상 점수를 학습
- 새로운 손실 함수가 필요
- 특징 표현과 이상 점수를 동시에 학습
- 이상 점수나 순위를 최적화
- 이상 점수 네트워크에 순서 또는 판별 정보를 통합하는 것이 중요
- 새로운 손실 함수의 설계가 성능에 큰 영향을 미침
8.1. Ranking Models
-
목적 : 이상성의 절대적/상대적 순서 관계와 관련된 관찰 가능한 순서형 변수를 기반으로 데이터 인스턴스를 정렬하는 순위 모델을 직접 학습함.
- 주요 연구 방향
- A. A self-trained deep ordinal regression model
- 자체 학습 심층 순서형 회귀 모델
- 이상과 정상 인스턴스에 대한 의사 레이블 사용
B. A pairwise relation prediction - 소수의 레이블된 이상과 대량의 레이블되지 않은 데이터 활용 - 인스턴스 쌍 간의 관계 학습
- 장점
- 손실 함수를 통한 이상 점수의 직접 최적화
- 이상의 정의에서 자유로움
- 기존 순위 학습 기술과 이론 활용 가능
- 단점
- 레이블된 이상 데이터 필요
- 학습된 이상과 다른 특성을 가진 새로운 이상에 대한 일반화 어려움
8.2. Prior-driven Models
-
목적 : 사전 분포를 사용하여 이상 점수 학습을 인코딩하고 유도함.
- 주요 특징
- 점수 학습 함수의 내부 모듈 또는 출력에 사전 확률 부여
- 베이지안 역강화학습 방법 활용
- 가우시안 사전 확률을 통한 이상 점수 인코딩
- 장점
- 사전 확률에 대한 직접적인 이상 점수 최적화
- 다양한 사전 분포 통합 가능
- 해석 가능한 이상 점수 제공
- 단점
- 보편적으로 효과적인 사전 확률 설계의 어려움
- 사전 확률이 실제 분포와 맞지 않을 경우 성능 저하
8.3. Softmax Likelihood Models
-
목적 : 훈련 데이터의 이벤트 우도를 최대화하여 이상 점수 학습함.
- 주요 특징
- 정상 인스턴스는 높은 확률, 이상은 낮은 확률 이벤트로 가정
- NCE(Noise Contrastive Estimation) 활용
- 쌍별 특징 상호작용 포착
- 장점
- 다양한 상호작용 통합 가능
- 특정 비정상 상호작용에 대한 충실한 최적화
- 단점
- 특징/요소가 많을 경우 계산 비용이 높음
- 부정 샘플 생성의 질에 크게 의존
8.4. End-to-end One-class Classification
-
목적 : 정상 여부를 판별하는 단일 클래스 분류기를 종단간 방식으로 학습함.
- 주요 특징
- GAN과 단일 클래스 분류 개념의 결합
- 적대적 생성 의사 이상에 대한 판별 학습
- 경계 데이터 인스턴스 생성 활용
- 장점
- 종단간 방식의 적대적 최적화
- 풍부한 적대적 학습과 단일 클래스 분류 이론 활용 가능
- 단점
- 생성된 참조 인스턴스의 실제 이상 유사성 보장 어려움
- GAN의 불안정성으로 인한 성능 변동
- 준지도 학습 시나리오로 제한됨
이 접근법은 기존의 이상 측정 방식에 의존하지 않고 신경망이 직접 이상 점수를 학습한다는 점에서 혁신적이며, 특징 표현과 이상 점수의 동시 학습을 통해 더 최적화된 결과를 얻을 수 있음.
특히, 저차원 표현 학습(CH1, CH2), 레이블된 데이터 활용(CH3), 노이즈 강건성(CH4) 등의 도전과제들을 해결하는데 기여함.
9. ALGORITHMS AND DATASETS
9.1. Representative Algorithms
-
각 범주의 대표적 알고리즘들의 주요 특성이 Table 2에 요약되어 있으며, 모델 설계와 관련된 주요 관찰 사항은 다음과 같음.
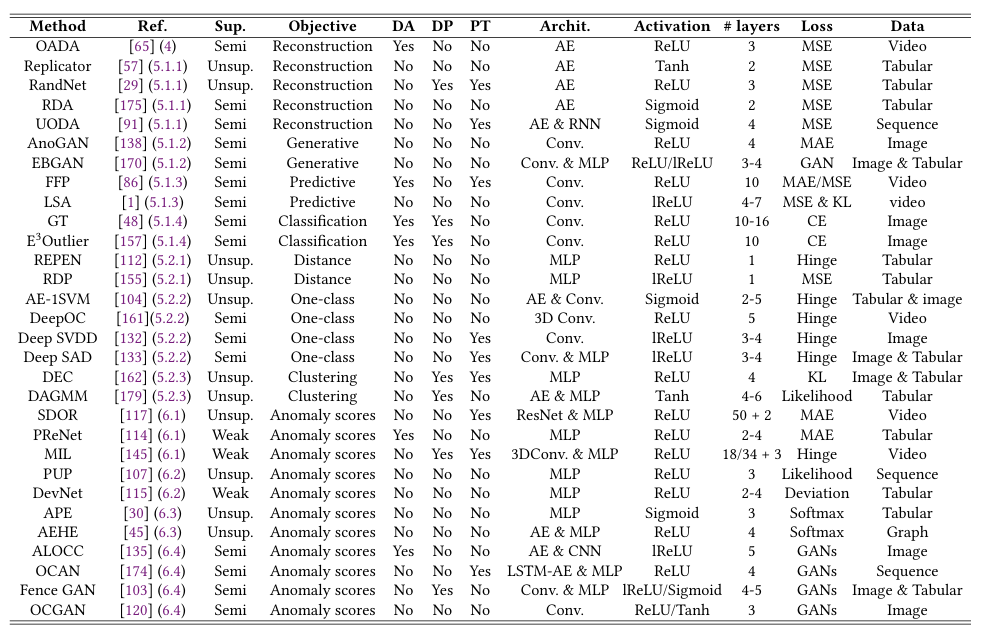
A. 운영 모드
- 대부분의 방법이 비지도 또는 준지도 방식으로 작동 B. 심층 학습 기법의 제한적 활용 : 데이터 증강, dropout, 사전 학습 등이 충분히 탐구되지 않음
C. 네트워크 구조 : 대부분 5개 이하의 네트워크 층으로 구성, 비교적 깊지 않은 구조
D. 활성화 함수
- (leaky) ReLU가 가장 널리 사용됨
E. 백본 네트워크
- 다양한 입력 데이터 유형을 처리하기 위해 다양한 백본 네트워크 사용 가능
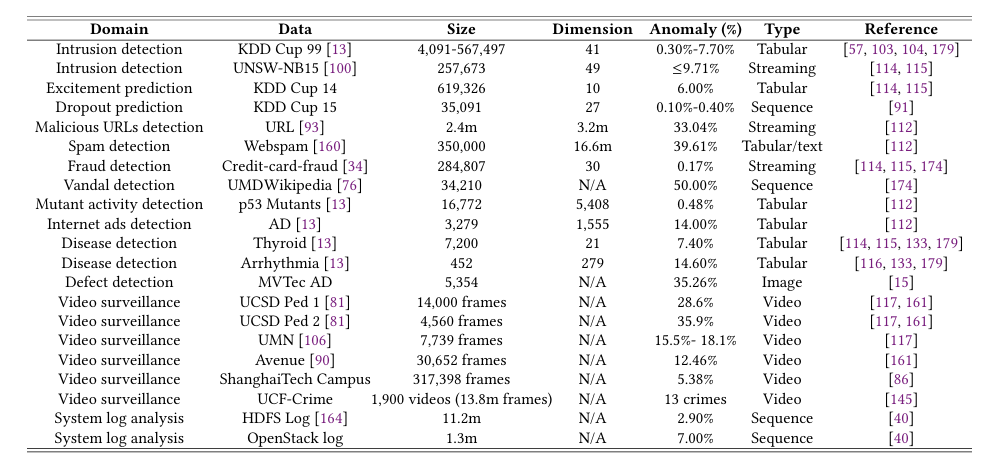
9.2. Datasets with Real Anomalies
- 이상 탐지 발전의 주요 장애물
- 실제 이상이 포함된 실세계 데이터셋의 부족
- 많은 연구들이 일반 분류 데이터를 변환하여 사용
- 이는 실제 이상 탐지 응용에서의 성능을 정확히 반영하지 못할 수 있음
- 실제 이상이 포함된 공개 데이터셋 특징
- 21개의 실세계 데이터셋을 Table 3에 요약
- 다양한 응용 도메인 포함
- 다양한 데이터 유형 포함
- 대규모 및/또는 고차원 복잡 데이터셋 위주 선정
-
심층 이상 탐지를 위한 도전적 테스트베드 제공
10. CONCLUSIONS AND FUTURE OPPORTUNITIES
10.1. Exploring Anomaly-supervisory Signals
- 정확한 이상 점수나 정상/비정상성의 표현적 표현을 학습하는데 정보가 풍부한 지도 신호가 핵심
-
기존 목적 함수들의 한계
A. 일반적이나 이상 탐지에 특화되지 않음
B. 기존 이상 측정 방식의 제약에 구속됨
-
향후 방향
A. 데이터 재구성과 GAN을 넘어선 새로운 이상 지도 신호 탐색
B. 도메인 지식을 활용한 도메인 중심 이상 탐지 개발
10.2. Deep Weakly-supervised Anomaly Detection
- Deep Weakly-supervised를 활용한 이상 인식 탐지 모델 학습
-
주요 연구 방향
A. 알려지지 않은 이상 탐지
a1. 제한된 레이블 이상에서 미지의 이상으로 일반화 a2. 모델의 일반화 가능성 이해와 성능 향상B. Data-efficient anomaly detection or Few-shot anomaly detection
b1. 제한된 레이블 이상에서 미지의 이상으로 일반화 b2. 모델의 일반화 가능성 이해와 성능 향상
10.3. Large-scale Normality Learning
- 대규모 비지도/자체지도 표현 학습의 성공을 이상 탐지에 적용
-
고려사항
A. 레이블되지 않은 데이터의 이상 오염 방지
B. 이상 오염에 대한 강건성 확보
C. 도메인/응용 특화적 접근 필요성
10.4. Deep Detection of Complex Anomalies
- 조건부/그룹 이상에 대한 심층 모델 연구 부족
- 다중 모달 이상 탐지의 미개척 영역
- 새로운 신경망 층이나 목적 함수 필요
10.5. Interpretable and Actionable Deep Anomaly Detection
- 현재는 정확도에만 중점
-
필요성
A. 모델 결정과 결과의 이해
B. 편향/위험 완화
C. 의사결정 행동 지원
-
접근법
A. 모델 독립적 설명 방식의 한계
B. 내재적 설명 능력을 가진 심층 모델 개발 필요
10.6. Novel Applications and Settings
-
새로운 연구 응용 분야
A. 분포 외 탐지(OOD)
a1. 훈련 분포에서 멀리 떨어진 인스턴스 탐지 a2. 세분화된 정상 클래스 레이블 가정B. Curiosity learning
b1. 희소 보상 강화학습에서의 보너스 보상 함수 b2. 이상 탐지와의 상호 보완 가능성C. IID
c1. 상호의존적/이질적 비정상성 처리 c2. 복잡한 시나리오에서 중요함D. 기타 응용
d1. 적대적 예제 탐지 d2. 생체인식 시스템의 위조 방지 d3. 희귀 재난 사건의 조기 탐지
11. Take away
- 데이터 증강, dropout, 사전 학습 등의 기법이 충분히 활용되지 않았으며, 실제 이상이 포함된 벤치마크 데이터셋이 부족함.
- 새로운 이상 지도 신호를 탐색하는 것이 필요하고, 대규모 정상성 학습 또한 필요함.
- 새로운 응용 분야인 분포 외 탐지나, 조기 재난 감지 등에 대해 확장 가능성이 높음을 알 수 있음.