발제자: 권혁선
발제일: 2024년 06월 05일
키워드: [AutoML] [ML resource provisioning]
URL: https://ieeexplore.ieee.org/abstract/document/10437119
발표자료: PDF
Why this paper
-
Network operator가 효율적으로 ML(Machine Learning) Workflow를 구성할 수 있는 프레임워크(AutoMLPoweredNetworks)를 제시
-
5G network로 부터 얻은 real operator data(ie. KPI)를 사용해 테스트를 진행
Summary of paper
1. Introduction
-
5G 서비스 기반(Service-Based) 아키텍쳐 측면에서 network operator들이 다양한 network data를 수동적(manually)으로 분석하고 관리해 서비스들을 배포하는 것은 쉽지 않음.
-
단순히 AI/ML을 사용해 network 결함을 예측하고 대응하는 방식도 제시되었지만 미국, 중국 인도처럼 수많은 디바이스들과 기지국이 필요한 지역에서는 CAPEX 및 OPEX의 측면에서 비효율적임.
-
결국, 제한된 리소스안에서 적절한 ML(Machine Learning) 모델을 선택하고 최적의 ML 자원을 network에 분배하는 자동화 프로세스가 중요해짐.
- 본 논문에서 이와 관련한 ML 프레임워크 를 제시.
2. Framework Workflow
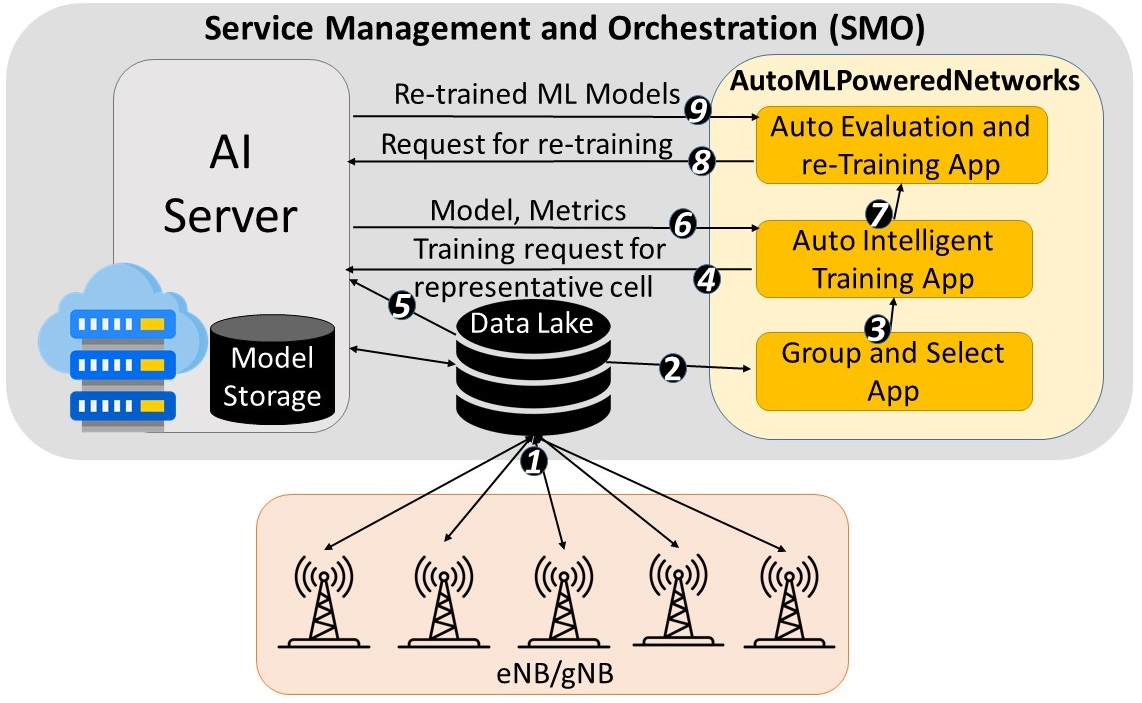
-
Network에서 이상 현상이 발견되면 SMO(Service Management and Orchestration)는 eNodeB/gNodeB로부터 data를 얻어 AI Server를 지원. 이때 data는 주기적으로 eNodeB/gNodeB로부터 수집되며 Data Lake에 저장.
- cell들은 수집한 network KPI를 기반으로한 “
Group and Select” 방식을 통해 graph상의 노드들로 mapping되며 그룹화.- 이때 대표(representitive) cell은 랜덤 혹은 graph에서 가장 많은 노드와 연결되어 있는 cell로 결정.
- cell들이 graph에 mapping되고 edge로 연결되는 과정에서 correlation metric을 이용.
-
결정된 대표 cell 및 그룹ID 그리고 correlation 알고리즘에 대한 정보가 “
Auto Intelligent Training App“에 공유. - ”
Auto Intelligent Training App“에서는 대표 cell을 위한 training & prediction 요청을 AI Server한테 전송.- cell중에 특정 그룹에 속하지 못한 cell들도 존재할 수 있으며 그러한 cell을 위한 training 요청도 AI Server한테 전송.
- AI Server는 training과 관련된 data를 Data Lake로부터 받아 대표 ML 모델을 학습시키고 학습된 모델을 Model Storage에 저장.
- 이 단계에서 학습되는 모델은 대표 cell을 위한 ML 모델
- 즉, 모델을 학습하는 과정은 AI Server에서 일어남.
-
학습을 마친 모델과 모델 정확도에 관한 정보가 다시 “
Auto Intelligent Training App“한테 전송. -
학습된 ML 모델은 대표 cell을 제외한 나머지 cell들에서의 예측에 사용되며 “
Auto Evaluation & Retraining App” 프로세스를 진행. - 정확도(Accuracy)가 너무 낮은 cell에 대해서는 Retraining 요청을 AI Server로 전송.
- 기존에 학습된 ML 모델은 유지하면서 예측 정확도가 떨어진 cell만을 위해서 ML 모델을 재학습(Retraining).
- Retraining된 ML 모델은 다시 “
Auto Evaluation & Retraining App“한테 전송.
3. Specific Method
3.1 Group and Select
- cell들 사이의 network KPI를 기반으로한 4가지의 correlation metric을 계산하고 그룹화 비율이 높은 metric을 선택.
- 그룹화 비율은 전체 cell 중 그룹으로 묶인 cell의 비율을 의미.
- Similarity Metric Correlation
- Pearson correlation
- 일반적으로 사용되는 correlation 기법으로 data가 특정 확률분포를 따른다는 가정을 전제.
- Spearman correlation
- Pearson correlation의 변형으로 data 기반이 아니라 data의 rank값을 토대로 correlation을 계산.
\(1- \frac{6 \sum_{i=1}^n (R(x_i) - R(y_i))^2}{n(n^2 - 1)}\) \(R(x_i)=Rank \ of\ x_i\) \(R(y_i)=Rank \ of \ y_i\) \(\overline{R(x)}=mean\ rank\ of\ x\) \(\overline{R(y)}=mean\ rank\ of\ y\)
- Kendall correlation
- 데이터들 사이의 기울기를 계산하고 기울기의 비율을 통해 correlation을 구함.
\(\frac{n_c-n_d}{n_c+n_d}\) \(n_c=number\ of\ concordant\ pairs\) \(n_d=number\ of\ discordant\ pairs\)
- DTW(Dynamic Time Warping) correlation
- 시계열 data에서 잘 사용되며 거리 matrix를 계산하여 총 거리가 최소가 되는 경로를 찾는 동적 프로그래밍 방식.
\(\frac{fastdtw(X,Y)}{n}\) \(fastdtw=\ 두\ 시계열\ data\ 사이의\ 최소\ DTW\) \(n=\ number\ of\ data\ point\)
- Pearson correlation
3.2 Auto Intelligent Training App
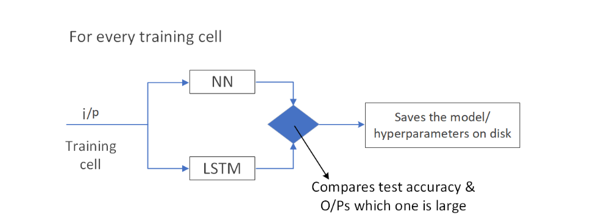
- ”
Group and Select” 프로세스에서 결정된 대표 cell들을 학습. - 대표 cell들이 모델 input으로 들어가고 SL(Supervised Learning)기반의 LSTM과 NN중 가장 좋은 정확도를 보이는 모델을 저장함.
3.3 Auto Evaluation and Retraining
- 저장된 대표 cell의 ML 모델을 기반으로 그룹내의 나머시 cell들의 KPI를 예측하고 특정 limit을 벗어나는 cell에 한하여 모델 retraining.
4. Result
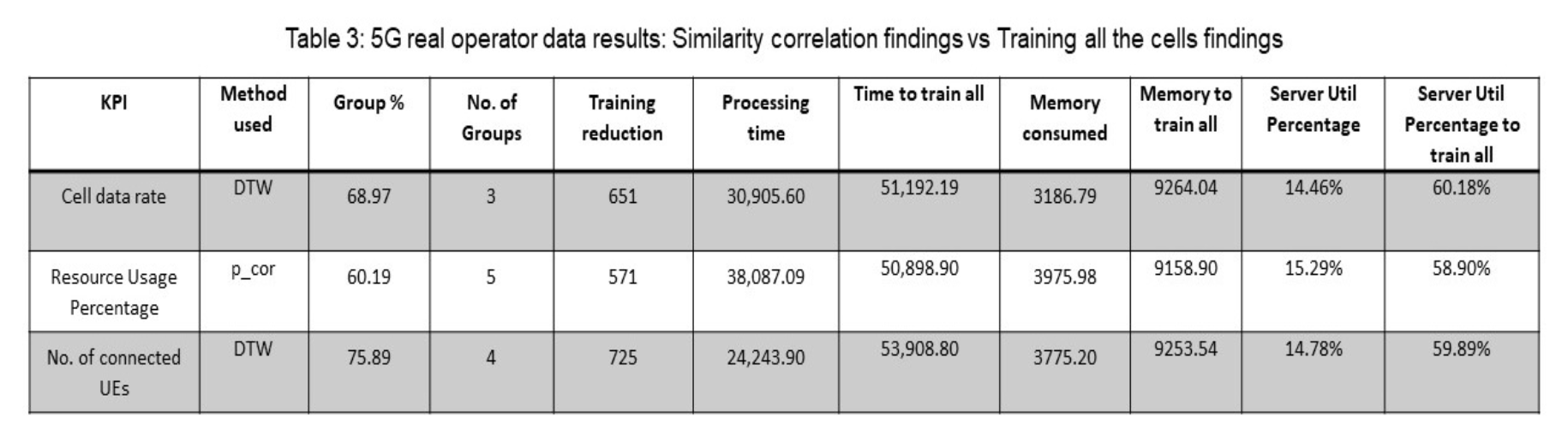
- Network KPI에 따라 선택된 correlation metric이 상이했지만 그룹 비율과 그룹의 수는 다소 비슷한 것을 확인할 수 있음.
- 프레임워크의 processing time의 경우 본 논문에서 제시한 방식이 모든 cell을 학습시키는 경우보다 많은 시간을 절약할 수 있음.
- Memory consumption 및 Server Utilization의 측면에서도 모든 cell을 학습시키는 경우보다 본 논문의 프레임워크를 사용할 때 효율적인 것을 확인할 수 있음.
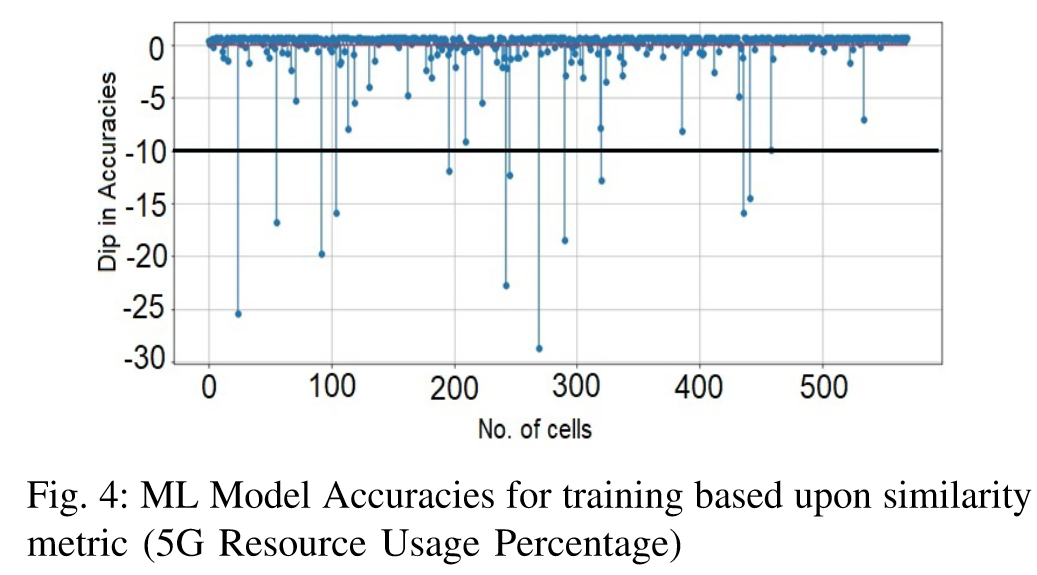
- 그리고 본 논문의 프레임워크에서 ML 모델을 재사용하는 방식은 전체 cell의 97.89%가 모델 정확도 limit에 들어오는 좋은 결과를 보임.