Anomaly Detection in Time Series: A Comprehensive Evaluation
발제자: 권재빈
발제일: 2024년 11월 14일
키워드: [Anomaly Detection] [Deep Learning] [Machine Learning] [Stastical Learning]
1. Why this paper
- 이상치 탐지 알고리즘 관련 지식 필요
- 동계학회 포스터 발표 예정
2. Summary of Paper
Abstract
- 현재, time series에서 이상치를 탐지하는 다양한 알고리즘이 개발됨. 하지만, 이들 알고리즘이 독립적으로 개발되어 서로 다른 알고리즘을 체계적으로 비교하거나 평가하는 연구가 부족.
- 71개의 최신 알고리즘을 선정해, 976개의 dataset에서 성능을 평가하여 이상치 탐지에 가장 적합한 알고리즘을 찾고자 함.
1) Anomaly Detection Wilderness
- 시계열 데이터(Time series data)는 시간 순서에 따라 연속적으로 배열된 포인트의 집합.
- 단일 변수로 구성된 시계열 데이터를 Univariate(하나의 채널), 여러 변수로 구성된 것을 Multivariate(다중 채널)라고 하고, Multivariate의 경우 변수 간 상관관계를 고려해야 함.
- 시계열에서 이상치는 일반적인 패턴과 다른 점을 의미하며, point anomaly와 subsequence anomaly로 구분.
- 이러한 이상치를 탐지하는 알고리즘은 distance-based, forecasting-based, statistical, signal processing, data mining, deep learning 방법이 있음.
- 기존의 많은 이상 탐지 연구와 평가들은 적은 수의 알고리즘을 대상으로 하거나 데이터셋이 제한적이며, 종종 연구자들의 편향적인 데이터셋 선택이나 비현실적인 환경에서 이루어짐.
- 알고리즘을 평가하기 위한 더 나은 기준과 포괄적인 평가가 필요.
- 총 158개의 시계열 이상 탐지 기법을 수집하여, 그 중 71개의 대표적인 알고리즘을 선택하고 976개의 dataset에서 평가하여, 정확도와 실행 시간 관점에서 성능을 분석하고자 함.
2) Time Series And Anomalies
A. 이상치(anomaly)의 정의
- 이상치(anomaly)는 point, context, sequence anomaly로 구분되며 time series를 고정된 길이의 부분 sequence로 나누고 각 부분의 정상, 비정상 여부를 embedding과 유사도, 그리고 거리 측정을 통해 판단.
B. 시계열 이상치 탐지와 관련한 분석
- Time series forecasting: 미래 값의 예측을 통해 관측 값과 예측 값 간의 차이를 이상치로 간주함. ex) DeepLSTM, ARIMA, Torsk, NumentaHTM.
- Time series classification: 전체 시계열을 특정 클래스에 할당하는 방법으로 탐지된 이상치를 특정 도메인 클래스에 따라 분류하는 후처리 단계에 사용됨. ex) PS-SVM, SR-CNN, COPOD, NoveltySVR.
C. Time series scoring
- Time series scoring 𝑆 = {𝑠1, 𝑠2, … , 𝑠𝑚}은 각 데이터 포인트 𝑇𝑖에 이상 점수 𝑠𝑖를 할당하는 이상치 탐지 알고리즘의 결과로, 𝑠𝑖 > 𝑠𝑗일 경우, 𝑇𝑖는 𝑇𝑗보다 더 이상적(anomalous).
- 다양한 알고리즘의 결과값을 이 정의에 따라 포인트별 anomaly score로 변환.
D. 평가 메트릭
- AUC-ROC: FPR(false positive rate=FP/N)를 사용하여 알고리즘을 평가.
- AUC-PR: PP(all predicted positive)에 대한 TP(true positive)의 비율(TP/PP)을 계산하여 알고리즘을 평가.
- AUC-PTRT: 시퀀스의 순서를 고려하여 AUC-PR의 엄격함을 완화함으로써 알고리즘을 평가.
- 각 평가 메트릭은 특정 임계값이 이상치와 정상 포인트를 완벽하게 분리할 수 있을 때 1.0의 완벽한 점수를 부여함.
3) Anomaly Detection Techniques
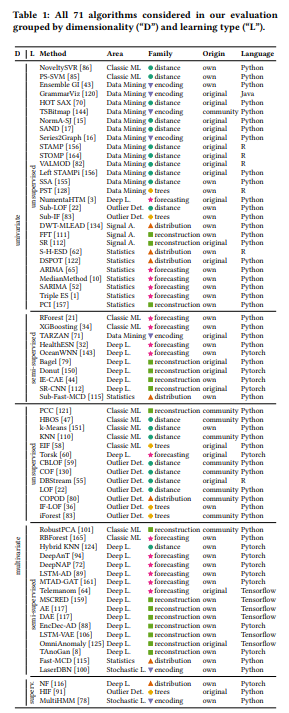
A. 연구 방법
- 다양한 연구 분야의 158개의 시계열 이상치 탐지 관련 논문에서 알고리즘을 수집했으며, 이 중 71개의 대표적인 알고리즘을 실험 평가에 포함하여 검토함.
B. 이상치 탐지 알고리즘의 학습 방식에 따른 분류
- Unsupervised: 사전 학습 없이 정상과 이상치를 구분.
- Supervised: 정상치와 이상치가 모두 포함되어 있는 training data를 통해 학습하여 정상과 이상치를 구분.
- Semi-supervised: 정상치만 있는 데이터를 통해 학습하여 비정상적인 시퀀스를 이상치로 구분.
C. 다양한 이상치 탐지 방법
- Forecasting Methods: current context window를 기반으로 이후 값을 예측하여 예측 결과와 실제 관측값 간의 차이를 이상치로 판단하는 방법.
- Reconstruction Methods: 정상 데이터 시퀀스를 저차원 잠재 공간(latent space)에 인코딩하고, 이를 복원한 결과와 원래 데이터 간의 차이를 통해 이상치를 판단하는 방법.
- Encoding Methods: 시퀀스를 잠재 공간에 표현하지만, 복원 없이 바로 잠재 공간에서 이상 점수를 계산하여 이상치 판단하는 방법.
- Distance Methods: 데이터를 이상치 시퀀스는 정상 시퀀스와 비교했을 때 거리가 크기 때문에 시퀀스 간의 거리를 측정하여 이상치 여부를 판단하는 방법.
- Distribution Methods: 비정상적인 시퀀스가 드문 패턴임을 기반으로 데이터의 분포를 모델링하고, 극단값 또는 분포의 꼬리 부분에 위치하는 시퀀스를 이상치로 간주하여 이상치 여부를 판단하는 방법.
- Isolation Tree Methods: 랜덤 트리를 사용해 샘플을 분리할 때, 이상치는 트리의 평균 경로 길이가 긴 것을 이용하여 이상치 여부를 판단하는 방법.
4) Experimental Evaluation
A. Environment and Setup
A-1) Algorithms
- TimeEval 툴을 사용해 각 알고리즘이 시간 및 메모리 제한을 초과하지 않도록 관리하며, 필요할 때는 알고리즘 출력을 이상치 점수로 변환하도록 함. 메모리나 실행 시간 제한을 초과한 일부 알고리즘들은 평가에서 제외함. (시간 제한: 2시간, 메모리 제한: 3GB)
A-2) Datasets
- 총 1,354개의 데이터셋을 다양한 소스로부터 수집하고 이상치가 명확히 라벨링된 데이터를 얻기 위해 GutenTAG라는 데이터 생성 툴을 사용해 194개의 합성 데이터셋을 생성함.
- 이상치가 없는 데이터셋, 10% 이상의 이상치를 가지는 데이터셋, 데이터 크기와 메모리 제한을 초과하는 데이터셋, 낮은 AUC-ROC 점수를 받은 데이터셋을 제거하여 976개의 데이터셋을 사용함.
A-3) Parameterization
- 최고의 성능에서 알고리즘을 비교하기 위해 다음 과정을 통해 (hyper-)parameter tuning을 진행함.
- Parameter initialization: 논문이나 레퍼런스에서 파라미터 값이 제공된 경우 그 값을 기본값으로 사용하고, 제공되지 않은 경우 간단한 테스트를 통해 적절한 값으로 초기화함.
- Parameter classification: 각각의 parameter를 Fixed, Dependent, Shared, Optimize parameter로 4개의 그룹으로 분류함.
- Fixed parameter: 변경할 필요가 없거나 실행 성능에만 영향을 미치는 매개변수 -> 기본값 유지하여 실험 진행함.
- Dependent parameter: 데이터셋 특성에 따라 값이 달라지는 매개변수 -> 매개변수를 동적으로 계산하는 규칙을 최적화하여 실험 진행함.
- Shared parameter: 여러 알고리즘에서 동일한 기능을 수행하는 매개변수로, 하나의 최적값을 공유할 수 있는 매개변수 -> 한 번의 최적화 과정을 통해 매개변수 설정하고, 해당 매개변수를 사용하는 알고리즘에서 동일하게 적용함.
- Optimize parameter: 위의 그룹에 속하지 않는 나머지 매개변수로, 각 알고리즘에 맞춰 개별적으로 최적화가 필요한 매개변수 -> 실험적으로 최적값을 개별적으로 찾아 실험 진행함.
- Parameter limitation: non-fixed parameter에 대해 매개변수의 범위를 제한함.
- Automatic optimization: TimeEval 툴을 사용해 설정된 각 매개변수를 다양한 값으로 자동으로 테스트를 진행함. 각 설정에 대해 실험을 수행한 후 AUC-ROC 점수가 가장 높은 매개변수 설정을 최종 선택함.
B. Quality of Results
B-1) AUC-ROC, AUC-PR and AUC-PTRT

- RI 1: Supervised algorithms은 훈련 시 이상치와 정상치에 대한 레이블 정보를 필요로 하나, unsupervised, semi-supervised algorithm보다 더 나은 성능을 보이지 않음.
- RI 2: Multivariate data에는 multivariate algorithms을 사용하는 것이 유리하고 univariate data에서는 univariate algorithms을 사용하는 것이 유리함.
- RI 3: 알고리즘 자체의 문제가 아닌, 실행 과정에서 메모리 및 시간 제한으로 인해 오류가 발생하는 경우가 많으므로 정밀한 검사 필요함.
- RI 4: AUC-ROC와 AUC-PR 지표로 동일한 알고리즘을 평가한 결과, 성능 순위가 일치하지 않는 경우가 존재하므로 경우에 따라 적절한 지표를 선택해야 함.
- RI 5: 모든 이상치 탐지 작업에 적합한 단일 알고리즘이 존재하지 않으며, 데이터셋의 특성과 이상치 유형을 고려하여 알맞은 알고리즘을 선택해야 함.
B-2) Reliability of Results
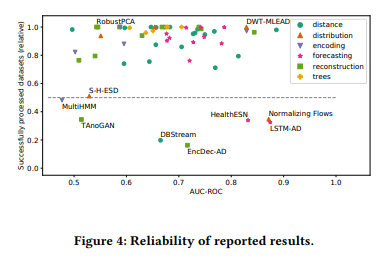
- 대부분의 알고리즘(87%)이 70% 이상의 데이터셋을 성공적으로 처리했으며, 일부 알고리즘(35%)은 99% 이상의 데이터셋을 성공적으로 처리함.
- 신뢰도가 52% 이하인 알고리즘들은 대부분 시간 초과나 메모리 초과, 내부 오류와 같은 문제를 겪음.
B-3) Anomaly Types and Dataset Characteristic
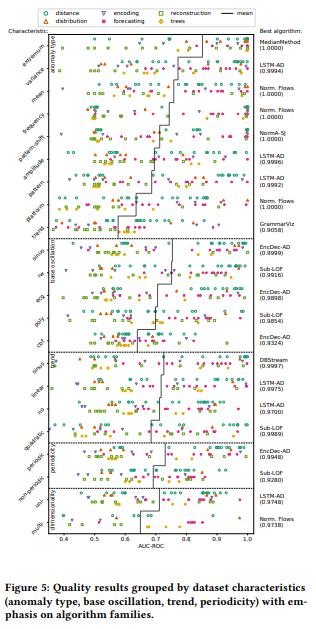
- RI 6,7: Extreme anomalies은 평균 AUC-ROC 점수가 0.8 이상으로 탐지가 가장 쉬운 유형으로 나타남. 특히, tree based algorithms과 point anomaly detector가 극값 탐지에서 좋은 성능을 보임. 반면 Trend anomalies은 평균 AUC-ROC 점수가 0.6 이하로, 탐지하기 가장 어려운 유형으로 나타남. 트렌드와 같은 점진적인 변화는 극적인 이상과 달리 탐지가 어려웠으며, encoding, distance and forecasting method만이 이를 효과적으로 탐지함.
- RI 8: Frequency and pattern-shift anomalies에서 distance, forecasting method는 이상치를 잘 탐지하고, reconstruction, tree based method는 성능이 낮게 나타남.
- RI 9: Base oscillation group에서는 주기적인 사인파인 경우 이상치를 탐지하기가 상대적으로 쉬웠으나, CBF에서는 성능이 낮게 나타남.
- RI 10: 주기적 시계열 데이터에서 정해진 패턴이 반복되므로 이상치 탐지 성능이 좋게 나타남. 주기적 데이터에서 16개의 알고리즘이 AUC-ROC 점수 0.90을 넘겼지만, 비주기적 데이터에서는 두 개의 알고리즘만이 높은 점수를 얻었음을 확인할 수 있음.
- RI 11: Reconstruction method는 전반적으로 낮은 AUC-ROC 점수를 기록했으나, EncDec-AD와 Donut 알고리즘은 다른 특성에서도 좋은 성능을 보임. Forcasting, distance method는 특히 좋은 성능을 보였으며, DeepAnT와 Sub-LOF와 같은 대표적인 알고리즘이 대부분에서 좋은 성능을 보임.
C. Runtime and Memory
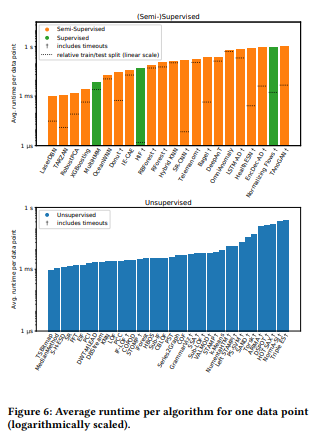
- RI 12: Supervised, semi-supervised algorithms은 Unsupervised algorithms에 비해 훈련 시간이 길기 때문에 실행시간이 많이 걸림.
- RI 13: 빠른 실행 시간을 가진 알고리즘이 반드시 높은 성능을 보이는 것은 아님.
- RI 14: 3GB 메모리 제한으로 인해 딥러닝 기반 알고리즘과 같이 높은 메모리 사용량을 가진 알고리즘은 메모리 초과 오류가 자주 발생하는 것을 확인할 수 있음.
3. Conclusion
이 논문은 다양한 시계열 이상 탐지 알고리즘을 포괄적으로 평가하여 각 알고리즘의 성능, 신뢰성, 그리고 특정 데이터셋 특성에 따른 차이를 분석한다. 실험을 통해 모든 알고리즘이 각기 다른 상황에서 강점과 약점을 가지고 있음을 확인했으며, 이는 데이터셋 특성에 따라 최적의 알고리즘 선택이 달라진다는 것을 보여준다. 추가적으로, 저자는 향후 연구에서 통합적이고 하이브리드한 이상치 탐지 시스템에 대한 연구, 알고리즘의 견고성과 확장성에 대한 연구, 그리고 parameter 자동 설정 알고리즘 개발이 필요함을 주장한다.
4. Take away
- 시계열 데이터에서 이상치 정의
- 이상치 탐지 알고리즘의 학습 방법에 따른 분류
- 시계열 데이터에서 이상치를 탐지하는 다양한 방법과 각 방법에 대한 원리
- 각 데이터셋에 따라 안정되고 일관된 성능을 보이는 알고리즘을 선택하는 것이 중요