발제자: 김건
발제일: 2024년 05월 10일
키워드: [Cell on/off] [Energy-saving] [Network] [Artificial Intelligence]
URL: https://ieeexplore.ieee.org/document/9682160
발표자료: PDF
Why this paper
- Energy-saving을 실현하고 QoS 기준을 만족하는 cell 온오프 알고리즘을 RL 문제로 정의
- 다양한 Operational mode에서 training된 RL agent들간의 성능을 비교
- 현실 세계를 모방한 replicatvie simulator를 활용하여 training한 모델 사용
Summary of paper
1. Introduction
- 연구 배경
- 사용자들이 요구하는 트래픽양의 증가에 따라 base station을 좁은 지역에 조밀하게 배치하고 있음
- 기존 네트워크 구성에서 Base station이 전체 소모 파워의 40%를 차지하고 있음
- Base station 수가 많아짐에 따라 energy-saving의 필요성이 증가함
- 연구 필요성
- Base station이 방출하는 탄소량은 환경 보존을 위해 감소되어야 함
- Energy saving을 통해 OPEX(Operation Expenditure: 운영 비용)을 절감할 수 있음
- 연구 문제
- 사용자들의 QoS(Quality of Service)를 보장하면서 Energy saving을 최대화
- 강화학습(RL: Reinforcement Learning)을 사용하여
- 연구 요약
- State: cell의 load와 on/off 상태
- Action: cell의 activation, deactivation threshold
- Reward: power reward + throughput reward
- Contribution
- Formulating an RL problem controlling a cell on/off algorithm in a way to minimize energy consumption while satisfying throughput constraints
- Proposing a range of operational modes on top of the trained RL agent
- Presenting experimental results with a replicative simulator
2. Related work
- Ye et al, HetNet 구조에서 강화학습 기반의 small cell on/off 알고리즘을 제안함. 이 때, Macro cell의 load를 고정시킨 채, 사용자들의 QoS 제약 조건을 만족시키는 것을 목적으로 함
- J. Ye and Y.-J. A. Zhang, “Drag: Deep reinforcement learning based base station activation in heterogeneous networks,” IEEE Transactions on Mobile Computing (TMC), 2019.
- Wu et al. 영역 안에 있는 모든 셀들의 parameter들의 조정을 통해 power saving operation을 최적화하는 방법을 제안함
- S. Wu, Y. Wang, and L. Bai, “Deep convolutional neural network assisted reinforcement learning based mobile network power saving,” IEEE Access, vol. 8, 2020.
3. System Model
3.1 Replicative Simulation
- 실제 상용 RAN 환경에서 강화학습을 바로 도입하는 것은 사용자들의 experience를 저하시킬 수 있으므로 바람직하지 않음
- Replicative simulation을 활용하여 RL(Reinforcement Learning) 에이전트를 훈련시킨 후 상용 RAN 환경에 도입하는 방법을 제안
- 실제 LTE 환경에 맞추어, 4개의 spectrum bands를 고려한 강화학습 알고리즘을 제안
-
Spectrum band마다 다른 RU를 사용하는 것을 활용하여, PRB utilization에 차이점을 부여함
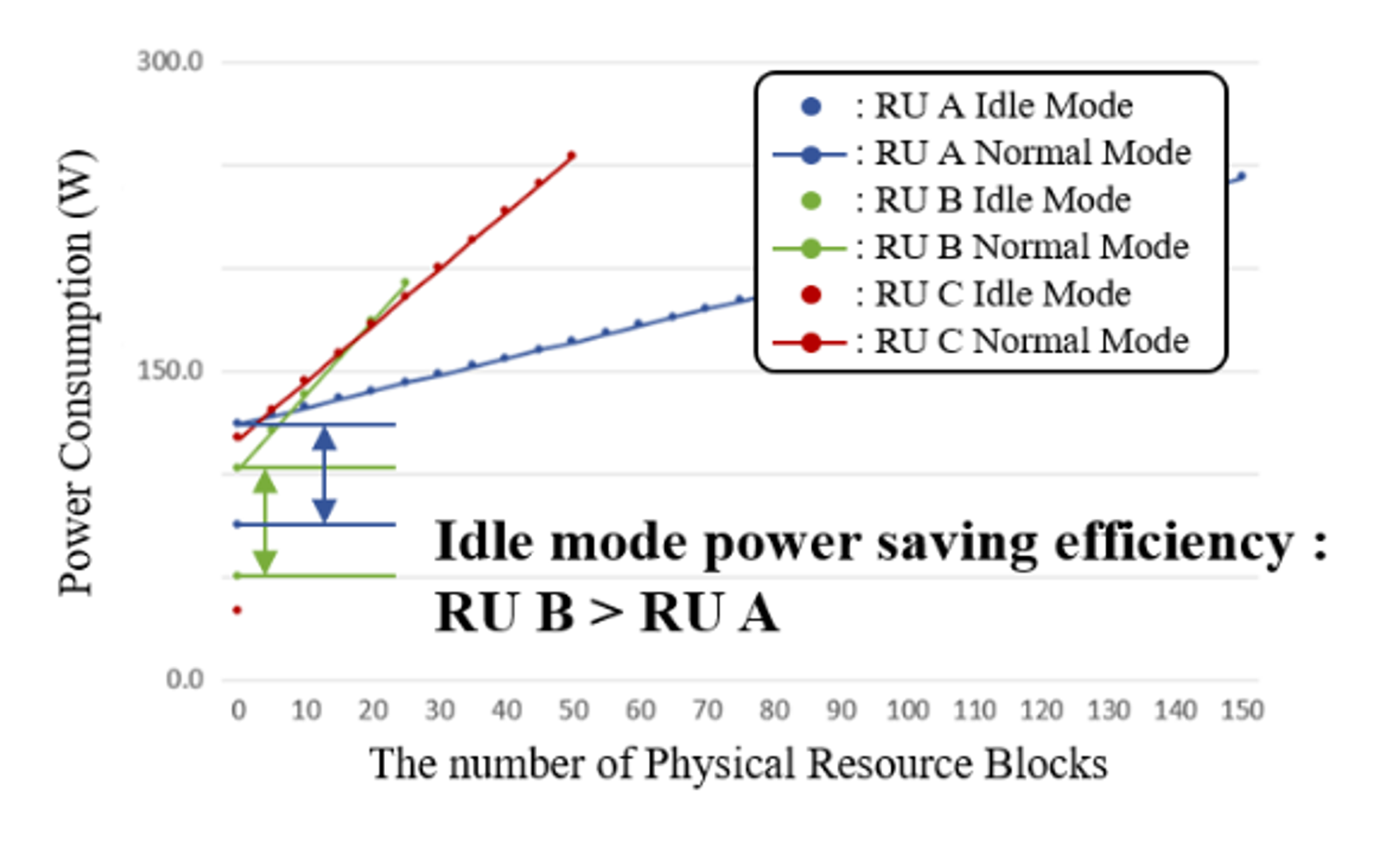
-
3.2 Cell On/Off Algorithm
💡 각 cell은 activation, deactivation 두 개의 독립적인 threshold 값을 가짐
- Cell이 off 되면, off된 cell에 있던 UE들은 RSRP를 기반으로 다른 cell들로 association 됨
- UE들이 distribute되는 것은 RSRP를 기준으로 간단한 load balancing 알고리즘을 활용함
- 최적의 threshold 값들을 찾아 QoS 제약조건을 만족시키며 최대 energy saving을 실현시킬 수 있음
3.3 Power Model
- Power는 PRB(Physical Resource Block) utilization에 따라 선형적으로 증가하게 모델링
- PRB utilization이 0이더라도 Power 소모가 0이 되는 것은 아님
4. Reinforcement Learning-based Customized Energy Saving Policy
4.1 RL Model Design
💡 RL model: PPO (Proximal Policy Optimization)
- 최적의 policy $\pi (a|s)$를 도출하기 위해 학습
- Continuous, discrete 상황에서도 모두 견고한 학습 능력을 보임
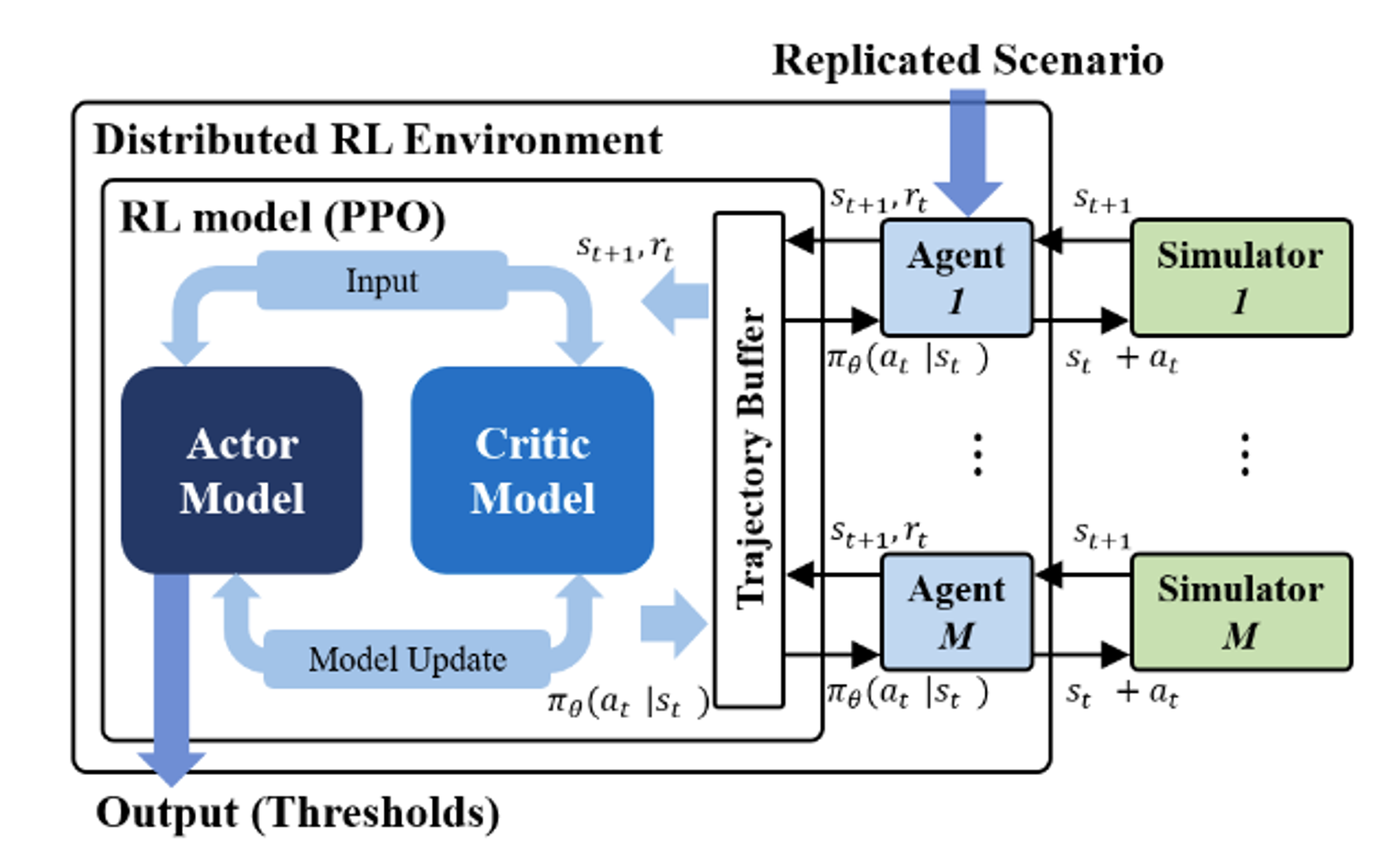
-
State
\[s_t^i=(l_(t-1)^i, …, l_(t-K)^i, c_(t-1)^i, ... , c_(t-K)^i)\]$𝑙_𝑡^𝑖$ : Load of cell 𝑖 at time 𝑘
$𝑐_𝑡^𝑖$: On/Off state of cell 𝑖
- Action
- Cell 𝑖 at time 𝑡에서의 activation, deactivation threshold 값들
- Reward
-
Power reward
𝑟_𝑝𝑜𝑤𝑒𝑟= $𝛽_0^𝑝+ 𝛽_1^𝑝 𝑙_𝑡^𝑖c$
- $𝛽_0^𝑝: 1$
- $β_1^p: -1/(P_max - P_min)$
-
Throughput reward
$r_{tput} = \begin{cases} β_0^tp+ β_1^{tp} k_t^i,\ \ \ \
if \ \ k_t^i>Q
β_0^d+ β_1^d k_t^i,\ \ \ \ \ \ \ otherwise \end{cases}$- 𝑞: Minimum throughput constraint
- $𝑘_𝑡^𝑖$: Throughput of cell 𝑖 at time 𝑡
- $𝛽_0^{𝑡𝑝}$: −𝑞/(𝑇_𝑚𝑎𝑥 −𝑞)
- $𝛽_1^{𝑡𝑝}$: 1/(𝑇_𝑚𝑎𝑥−𝑞)
- $𝛽_0^𝑑$: −10𝑞
- $𝛽_1^𝑑$:10
-
Total reward = Power reward + Throughput reward
$r_t= \sum(α* r_power+(1-α)*r_{tput} )$
- where $\alpha$ is a real number satisfying $0 < \alpha < 1$
-
4.2 Various Operational Modes
- Control과 prediction의 period를 변화시키면서 학습 performance와 required computation power 사이의 균형을 맞출 수 있음
4.3 Comparative Evaluation
4.3.1 Simulation and System Settings
- 가장 낮은 spectrum bands를 사용하는 cell은 항상 켜져있어야 함 (Macro cell은 항상 켜져있어야 함, 커버리지를 담당하므로)
- 1일동안 activation, deactivation threshold를 최적화하는 학습을 진행함
4.3.2 Evaluation Scenarios
-
Traffic volume을 변화시켜 다양한 시나리오들을 생성
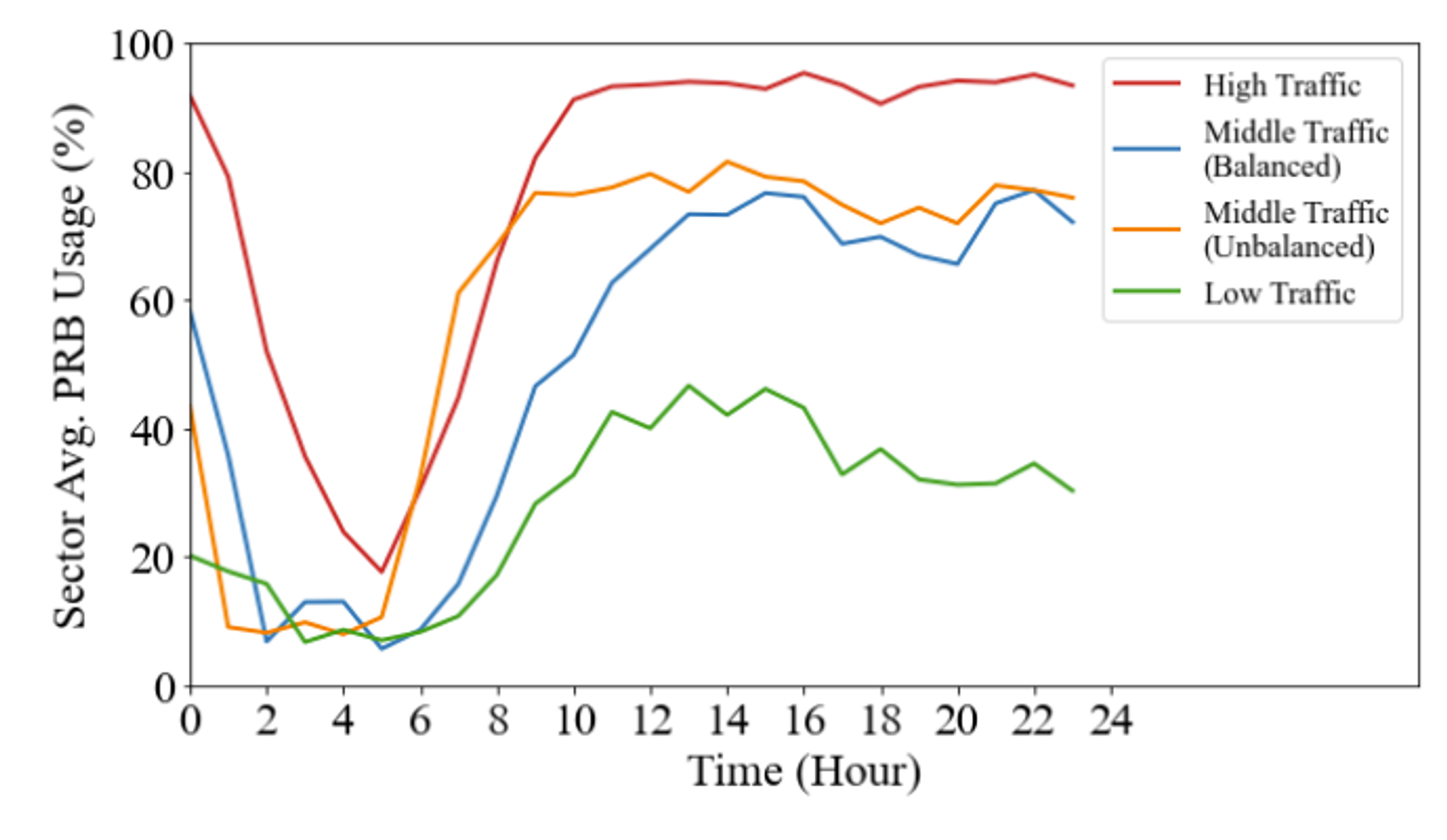
-
Cell On/Off Operating Options은 아래의 그림과 같음
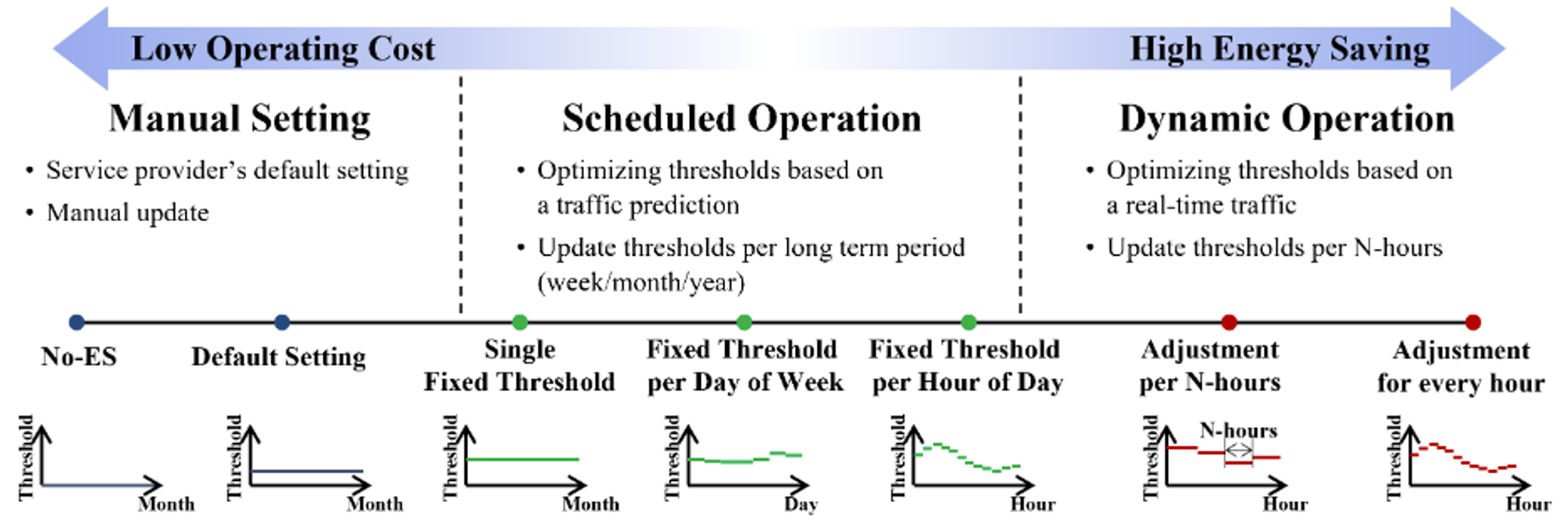
4.3.3 Evaluation Results
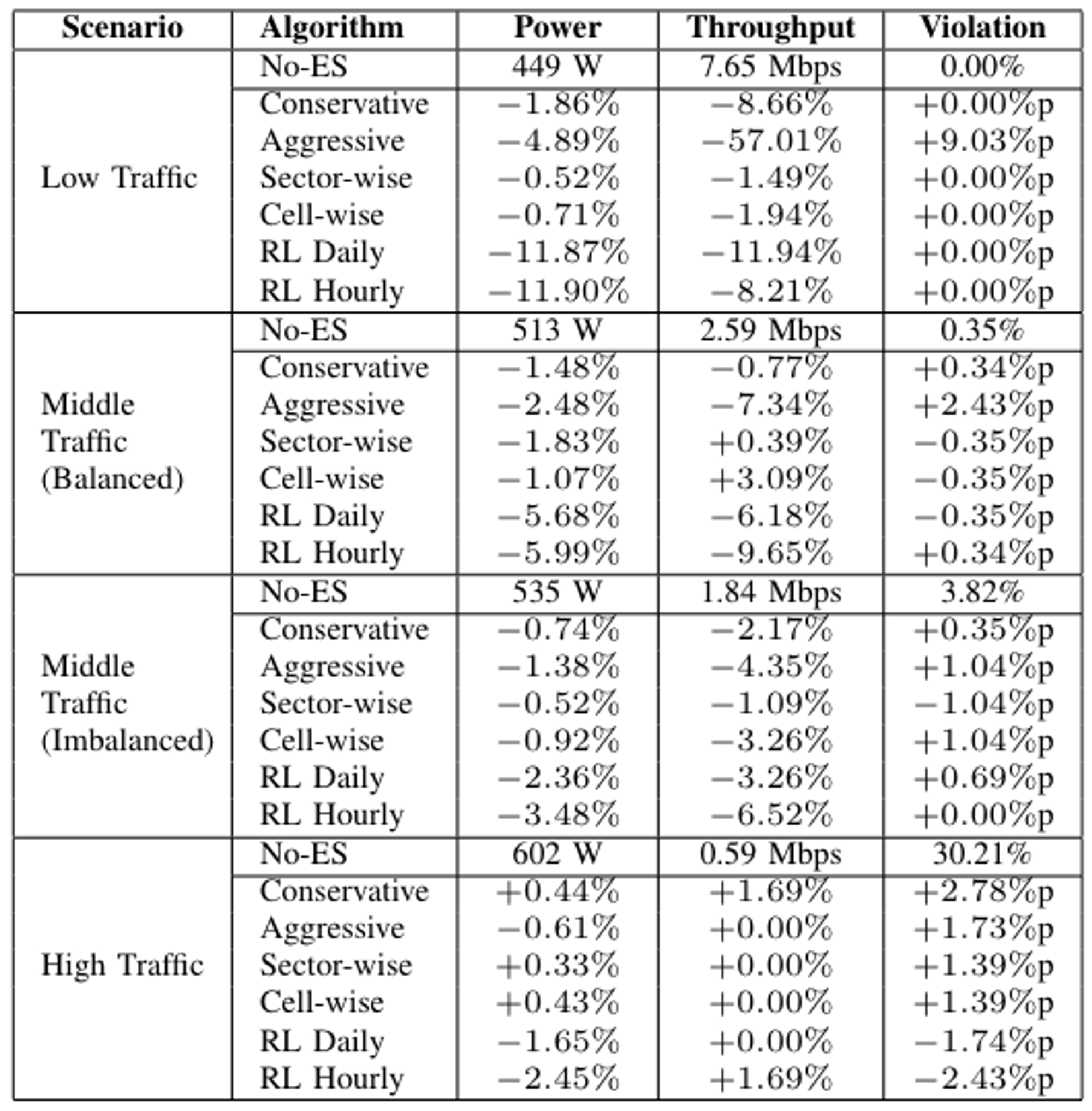
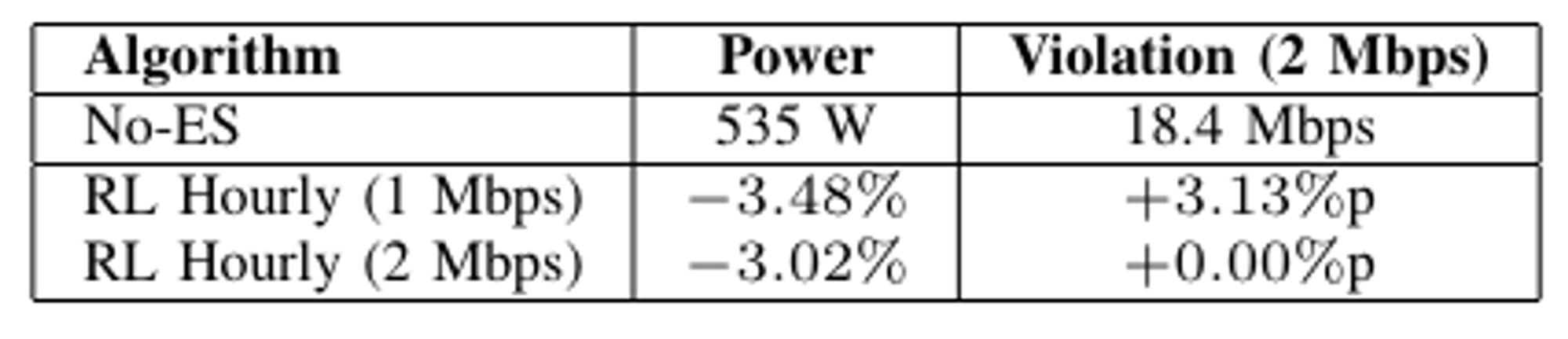
- RL을 기반으로 한 알고리즘들이 Power saving에서 압도적으로 좋은 성능을 보임
- RL-hourly가 가장 좋은 energy saving을 보임을 알 수 있음
- Throughput 제약을 더 엄격하게 설정한 후 학습 진행
- 예상과 다르게 constraints이 더 느슨할 때 많은 에너지를 소모하게 됨
5. Conclusion
- 본 논문에서 제안한 RL 알고리즘이 throughput 제약조건을 만족시키며 가장 높은 energy saving을 달성함
- 네트워크 status prediction을 같이 사용하게 되면 base station의 CAPEX를 더 효과적으로 줄일 수 있음
Take away
- 실제 환경을 반영하여 주파수 대역을 고려한 cell on/off 알고리즘
- 강화학습을 위해 필요한 파라미터들을 꼭 가져갈 것
- 강화학습을 실제 상황에 바로 도입하는 것이 아니라 replicative simulator에서 학습 후 RAN에 도입한다는 것 기억하기